Cloudflare Workers: serverless en el edge sin servidor que mantener

Un Jedi no deja que el Imperio controle sus rutas de comunicación.
bit.ly no es gratis, lo pagas con tus clics. Registra quién hace clic, desde dónde, en qué dispositivo, a qué hora. Construye un perfil de comportamiento de tu audiencia — que es tuya — y lo vende. El acortador es el producto. Tú eres el canal de adquisición.
Necesitaba acortar URLs para los artículos del blog. La respuesta obvia era bit.ly. La respuesta que usé fue un Worker de Cloudflare.
go.jaimealberto.io/blog. Sin servidor. Sin base de datos. Sin que nadie registre los clics de mis lectores. Y el plan gratuito aguanta 100.000 peticiones al día.
Índice
- Cómo funciona un Cloudflare Worker
- Casos de uso reales para homelab y sysadmin
- El acortador que construí: go.jaimealberto.io
- Workers KV: almacenamiento clave-valor en el edge
- Plan gratuito: qué cubre y cuándo se queda corto
Cómo funciona un Cloudflare Worker
Un Worker es código JavaScript que Cloudflare ejecuta en su propia red. La petición entra, el Worker corre en el nodo más cercano al usuario — normalmente a menos de 20ms de cualquier punto del mundo — y tu servidor no se entera de que esa petición existió.
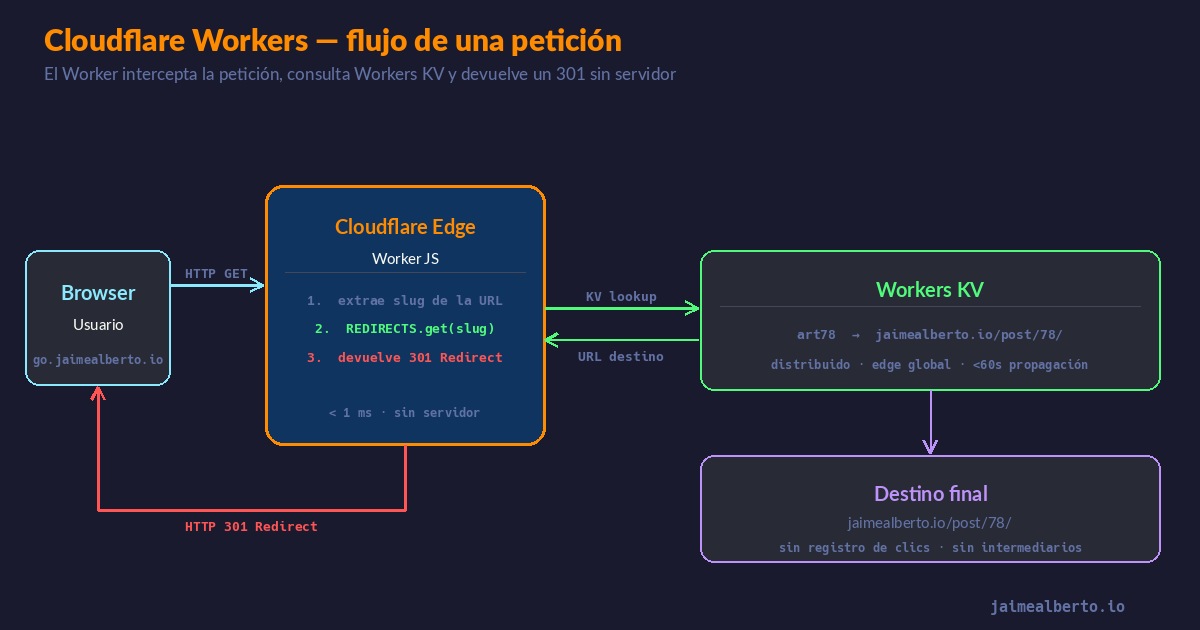
No arrancas ningún servidor. El Worker responde a la petición y desaparece — nada corre en segundo plano, nada consume recursos en reposo. Olvídate de parchear la máquina, monitorizar procesos o gestionar alertas de OOM a las 3 de la mañana.
Yo llevo dos años sin tocar la infraestructura del acortador. Ni actualizaciones, ni monitorización, ni un solo reinicio. Eso no pasa con un servidor.
Para persistencia tienes Workers KV, que es exactamente lo que montamos a continuación.
El modelo de programación es el de un service worker del navegador: interceptas el evento fetch, procesas la petición y devuelves una respuesta.
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
return new Response('Hola desde el edge', { status: 200 })
}
Eso es todo.
Casos de uso reales para homelab y sysadmin
Un Worker encaja donde necesitas lógica HTTP sin levantar infraestructura:
Webhook receptor
Tengo n8n y Gotify corriendo en la red interna, sin exponer ningún puerto. Cuando GitHub necesita notificarme algo, no puede llegar directamente al servidor. El Worker recibe el webhook, valida la firma y lo reenvía vía Cloudflare Tunnel. Ningún servicio expuesto. Nadie sabe que n8n existe.
Es el patrón que más repito en el homelab: mantener los servicios internos completamente opacos a internet y usar el Worker como portero.
Redirect inteligente con lógica
Un redirect estático lo hace cualquier .htaccess. Un Worker puede hacer redirects con lógica: por user-agent, por geografía, por hora del día, por cualquier cabecera HTTP. Esto me fue genial en un cliente para que la web fuera más rápida según la geolocalización de las IPs que se conectaban a una página de venta online.
Un .htaccess no sabe quién te llama. Un Worker sí. O para lo que construí a continuación.
API proxy que oculta credenciales
Si metes una clave de API en el código del navegador, cualquiera la ve en los devtools. El Worker actúa como proxy: el navegador llama al Worker, el Worker añade la clave — guardada como secreto de Cloudflare, nunca expuesta — y reenvía la llamada. La clave no toca el cliente. Es lo que uso para las APIs externas en jaimealberto.io.
El acortador que construí: go.jaimealberto.io
Quería algo útil de verdad, no un “Hello World”. Los artículos del blog tienen URLs largas — cuando los comparto en LinkedIn o en otros sitios, https://www.jaimealberto.io/post/78_cloudflare_workers/ no es elegante. Un acortador propio, en mi dominio, sin depender de bit.ly ni similares, era el caso perfecto.
El resultado: go.jaimealberto.io/blog, go.jaimealberto.io/linkedin, go.jaimealberto.io/art78. Todo gestionado desde la API de Cloudflare, sin panel de control, sin base de datos.
El código del Worker
El Worker es deliberadamente simple. Recibe la petición, extrae el slug de la URL, lo busca en KV y redirige:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
const url = new URL(request.url)
const slug = url.pathname.slice(1)
if (!slug) {
return Response.redirect('https://www.jaimealberto.io', 301)
}
const target = await REDIRECTS.get(slug)
if (target) {
return Response.redirect(target, 301)
}
return new Response('Not found', { status: 404 })
}
REDIRECTS es el binding al KV namespace — Cloudflare lo inyecta en el contexto del Worker automáticamente. No hace falta instalar ningún cliente, configurar URLs de conexión ni gestionar credenciales. La variable simplemente está ahí.
Despliegue vía API
Lo desplegué sin Wrangler (el CLI oficial de Cloudflare), usando directamente la API REST. Las credenciales viven en un fichero local con permisos 600 y nunca salen de ahí. Tres llamadas en orden: crear el KV namespace, subir el script con su binding, y registrar la ruta DNS.
# 1. KV namespace
curl -X POST "https://api.cloudflare.com/client/v4/accounts/$CF_ACCOUNT_ID/storage/kv/namespaces" \
-H "X-Auth-Email: $CF_EMAIL" \
-H "X-Auth-Key: $CF_GLOBAL_KEY" \
-H "Content-Type: application/json" \
--data '{"title": "go-redirects"}'
# 2. Worker con binding al KV
curl -X PUT "https://api.cloudflare.com/client/v4/accounts/$CF_ACCOUNT_ID/workers/scripts/go-jaimealberto" \
-H "X-Auth-Email: $CF_EMAIL" \
-H "X-Auth-Key: $CF_GLOBAL_KEY" \
-F "[email protected];type=application/json" \
-F "[email protected];type=application/javascript"
# 3. DNS AAAA + ruta de zona
curl -X POST "https://api.cloudflare.com/client/v4/zones/$CF_ZONE_ID/dns_records" \
--data '{"type":"AAAA","name":"go","content":"100::","proxied":true}'
curl -X POST "https://api.cloudflare.com/client/v4/zones/$CF_ZONE_ID/workers/routes" \
--data '{"pattern":"go.jaimealberto.io/*","script":"go-jaimealberto"}'
El metadata.json declara el binding entre el script y el KV namespace:
{
"body_part": "script",
"bindings": [
{ "type": "kv_namespace", "name": "REDIRECTS", "namespace_id": "f2ef42c8..." }
],
"compatibility_date": "2024-01-01"
}
El DNS AAAA apunta a 100::, la dirección anycast de Cloudflare Workers. Con proxy activado y la ruta de zona configurada, go.jaimealberto.io/* ya entra al Worker:
curl -I https://go.jaimealberto.io/blog
# HTTP/2 301
# location: https://www.jaimealberto.io/
Script para añadir slugs
Para no tener que recordar los comandos curl, un script de una línea útil:
#!/bin/bash
# go-add.sh <slug> <url>
source ~/.config/cloudflare/api_tokens.env
curl -s -X PUT \
"https://api.cloudflare.com/client/v4/accounts/$CF_ACCOUNT_ID/storage/kv/namespaces/$KV_ID/values/$1" \
-H "X-Auth-Email: $CF_EMAIL" \
-H "X-Auth-Key: $CF_GLOBAL_KEY" \
-H "Content-Type: text/plain" \
--data "$2" && echo "✓ go.jaimealberto.io/$1 → $2"
./go-add.sh art78 https://www.jaimealberto.io/post/78_cloudflare_workers/
# ✓ go.jaimealberto.io/art78 → https://www.jaimealberto.io/post/78_cloudflare_workers/
Workers KV: almacenamiento clave-valor en el edge
Workers KV es el almacenamiento persistente de Workers. Distribuido globalmente, eventualmente consistente — y aquí viene lo que nadie explica bien — optimizado para lecturas frecuentes y escrituras ocasionales. El patrón exacto de un acortador de URLs: escribes el slug una vez, se lee miles de veces.
La API es minimalista:
// Leer
const value = await REDIRECTS.get('clave')
// Escribir (desde fuera, vía API REST)
// PUT /accounts/{id}/storage/kv/namespaces/{ns}/values/{key}
// Borrar (desde fuera, vía API REST)
// DELETE /accounts/{id}/storage/kv/namespaces/{ns}/values/{key}
Los writes desde el Worker en sí son posibles pero el KV está diseñado para ser escrito desde fuera (API, Wrangler, scripts) y leído desde dentro. Para casos de escritura frecuente desde el propio Worker existe Durable Objects, que es otro producto diferente.
Cuándo no usar KV: si necesitas consistencia fuerte, es decir, leer siempre el último valor escrito al instante, KV no es la herramienta. La propagación global puede tardar hasta 60 segundos. Para el acortador no importa. Un slug nuevo tarda un minuto en llegar a todos los edge nodes, y en la práctica ni me he dado cuenta del retraso desde que lo monté.
Plan gratuito: qué cubre y cuándo se queda corto
Para el 95% de lo que monto en el homelab, el plan gratuito da de sobra. Y eso que soy bastante generoso con los casos de uso:
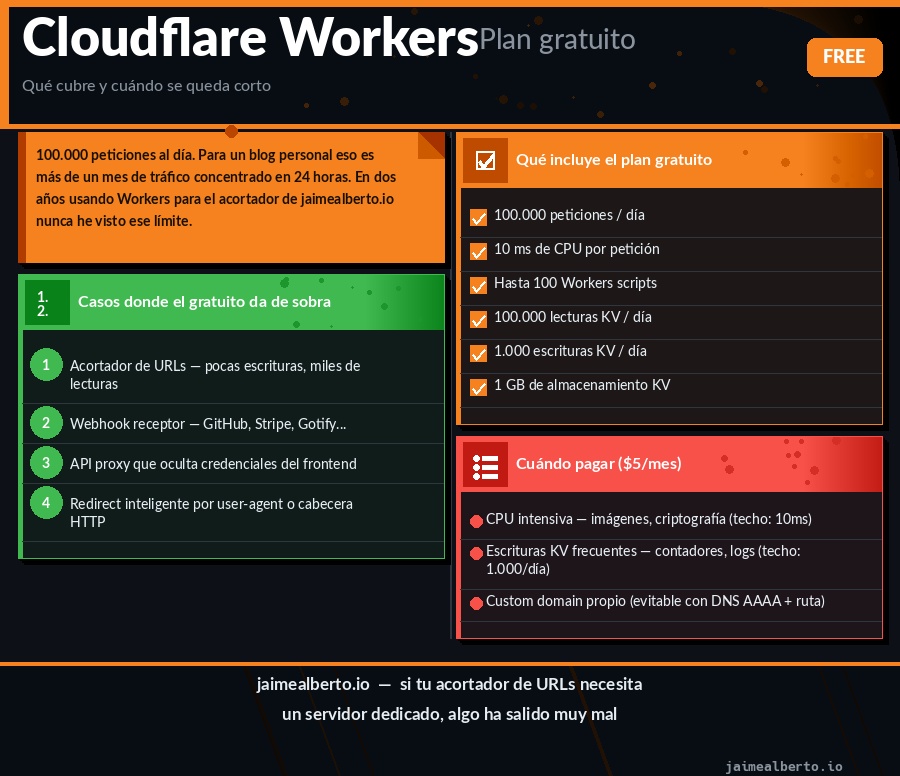
Con 100.000 peticiones diarias sirves más tráfico del que genera un blog personal en un mes. Para un acortador, un webhook receptor o un proxy de API, nunca vas a ver el límite.
Donde se queda corto:
- CPU intensiva: 10ms de CPU por petición es suficiente para lógica simple, pero no para procesamiento de imágenes, criptografía pesada o parsing de documentos grandes. Para eso existe el plan de pago con 30ms garantizados y opción de burst.
- Escrituras KV frecuentes: 1.000 escrituras diarias limita los casos de uso donde el Worker escribe en cada petición (contadores, logs). Para eso, Durable Objects.
- Subdominio propio: en el plan gratuito puedes usar Workers en tus dominios existentes via rutas (como hice aquí), pero el custom domain dedicado al Worker requiere el plan de pago. Con la técnica del DNS AAAA + ruta se evita esta limitación. Si gestionas tu DNS con la API de Cloudflare, el proceso es el mismo que en DDNS gratuito con Cloudflare.
Las configuraciones y ejemplos de código descritos se han probado en infraestructura propia con el plan gratuito de Cloudflare vigente en la fecha de publicación. Los límites y condiciones del plan pueden cambiar — verifica siempre la documentación oficial antes de usar en producción. El autor no asume responsabilidad por costes inesperados ni por daños derivados de su aplicación sin las adaptaciones necesarias.
Hace unos años, “serverless” significaba Lambda de AWS y una factura impredecible. Me quedé a cuadros la primera vez que revisé el detalle de costes de un proyecto en producción con Lambda: transferencia de datos, peticiones contadas al milisegundo, redondeos hacia arriba. Cloudflare Workers cambió esa ecuación, me puse con ello y le ahorré dinero a un cliente. La unidad de trabajo es la petición — no el tiempo de servidor encendido esperando. El precio de partida es cero, y el código corre donde está el usuario porque Cloudflare tiene edge nodes a menos de 20ms de cualquier punto del mundo.
Para el homelab no es la navaja suiza de todos los días — para eso tenemos Proxmox y los contenedores de siempre. Es lo que usas cuando levantar un servidor sería matar moscas a cañonazos. Un acortador de URLs no necesita un contenedor Docker. Para un webhook tampoco tiene sentido levantar un VPS con su systemd, su cron y su cuota mensual.
La industria sobredimensiona por defecto. Levantamos servidores para lo que cabe en una función, pagamos cuotas mensuales para lo que resuelve un script de 15 líneas. El cañonazo sale caro — en dinero, en tiempo y en complejidad que hay que mantener para siempre.
A veces la infraestructura correcta es la que no tienes que mantener.